regress
- 官方文档:
- 简介:
一维数据线性回归
regress 读取一个或多个表数据(也可从标准输入读取),确定每个分段最佳的线性[加权] 回归模型 \(y(x) = a + b x\) 。用户可自己指定输出哪些数据和模型。默认情况下,将 所有的输入数据作为一个整体来确定模型,但也可将数据分为等间距的数据段,在每段分别确定 模型。除了确定最贴近的模型外,该模块还可以输出所有可能的不同斜率的回归模型,这在分析 居于很多离群数据时非常有用。
备注
如果用户需要对 x 和 y 坐标的对数结果做拟合,可以使用 -iflags 选项在读数据后
将其转换为对数坐标
语法
gmt regress
[ table ]
[ -A[min/max/inc][+f[n|p]] ]
[ -Clevel ]
[ -Ex|y|o|r ]
[ -Fflags ]
[ -N1|2|r|w ]
[ -S[r] ]
[ -T[min/max/]inc[+i|n] |-Tfile|list ]
[ -V[level] ]
[ -W[w][x][y][r] ]
[ -Z[+|-]limit ]
[ -aflags ]
[ -bibinary ]
[ -bobinary ]
[ -dnodata[+ccol] ]
[ -eregexp ]
[ -fflags ]
[ -ggaps ]
[ -hheaders ]
[ -iflags ]
[ -oflags ]
[ -qflags ]
[ -sflags ]
[ -wflags ]
[ --PAR=value ]
输入数据
- table
一个或多个ASCII或二进制表数据。若不提供表数据,则会从标准输入中读取。
可选选项
- -A
- -A[min/max/inc][+f[n|p]]
该选项有两个用法:
(1) 寻找回归的完整范围,而不是确定最佳拟合回归。以 inc 度为步长(默认 [-90/+90/1]),检查斜率角在 min 和 max 之间的所有可能回归线。 对于每个斜率,根据回归类型
-E和不拟合范数-N设置来确定最佳截距。 对于每个数据分段,会在指定的角度范围内报告 angle 、 E 、 slope 、 intercept 这四列数据。 该范围内的最佳模型参数将写入分段头中,并在详细信息模式 (-Vi ) 下报告。(2) 除
-N2 外,附加 +f 以强制最佳回归仅考虑给定的受限角度范围 [默认考虑所有角度]。 可分别使用 +fn 或 +fp 表示负斜率或正斜率。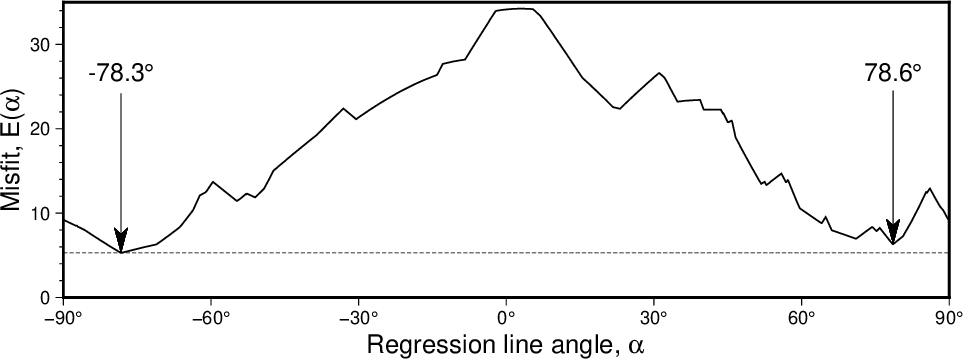
扫描斜率
-A以观察使用 LMS (-Nr ) 准则的完全正交回归的不拟合度量 (misfit) 随直线角度的变化情况。这里我们可以看到,最佳解对应的直线角度为 -78.3 度,但在 78.6 度处存在另一个几乎同样好的局部极小值。
- -C
- -Clevel
设置用于回归置信带 (confidence bands) 可选计算的置信水平(以 % 为单位)[默认为 95]。该选项仅在
-F包含输出列 c 时使用。
- -E
- -Ex|y|o|r
线性回归类型,即选择应计算的不拟合 (misfit) 类型。可从以下选项中选择:
x : x 对 y 的回归,即不拟合是从数据点到回归线的水平方向测量。
y : y 对 x 的回归,即不拟合是从垂直方向测量 [默认]。
o :正交回归,即不拟合是从数据点到直线上最近点的正交距离测量。
r :缩减主轴回归 (Reduced Major Axis),即不拟合是垂直和水平不拟合的乘积 [y]。
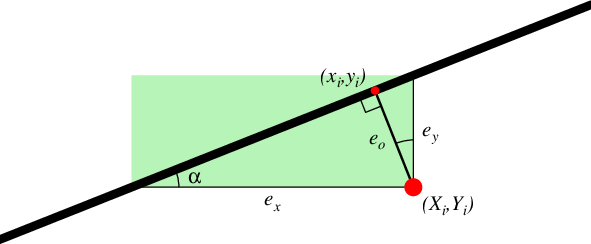
四种不拟合类型。对于 k = x, y 或 o,会最小化 \(e_k\) 长度的平方和。对于
-Er,则最小化绿色区域的面积之和。
- -F
- -Fflags
选择输出数据的列的组合,输出顺序将与指定的顺序一致。可从以下选项中选择:
x :观测值 x。
y :观测值 y。
m :模型预测值。
r :残差(残差 = 数据减去模型)。
c :回归的对称置信区间,参见
-C以指定置信水平。z :标准化残差或所谓的 z 分数 (z-scores)。
w :离群值权重(0 或 1)。对于
-Nw,这些是重新加权最小二乘法 (Reweighted Least Squares) 的权重。
默认值为 [xymrczw]。
使用 -Fp 会输出包含 12 个模型参数的单条记录:
npoints xmean ymean angle misfit slope intercept sigma_slope sigma_intercept r R n_effective
注意: R 只能在选择
-Ey 时设置。
- -N
- -N1|2|r|w
选择用于不拟合 (misfit) 计算的范数。可从以下选项中选择:
1 : \(L_1\) 度量,绝对残差的平均值。
2 :最小二乘法,平方残差的平均值 [默认值为 2]。
r :LMS,平方残差的最小中位数。
w :RLS,重新加权最小二乘法:在通过 LMS 识别并移除离群值后,计算平方残差的平均值。
传统回归使用 \(L_2\),而 \(L_1\) 尤其是 LMS 在处理离群值时更为稳健。 如前所述,RLS 意味着先进行初始 LMS 回归,用其识别数据中的离群值并分配零权重,然后使用 \(L_2\) 范数重新进行回归。
- -S
- -S[r]
限制输出哪些记录。默认情况下,所有数据记录都将按照
-F指定的格式输出。使用本选项排除被回归算法识别为离群值的数据点。 使用 -Sr 来反转此行为,仅输出离群值记录。
- -T
- -T[min/max/]inc[+i|n] |-Tfile|list
在参数指定的等间距点处评估最佳拟合回归模型。如果仅给出了
-Tinc,将把 min 和 max 重置为每个分段中 x 的极值。 若要完全跳过模型评估,使用-T0。详细请参见 生成一维数组 。
- -V
- -V[level]
设置 verbose 等级 [w]。 (参数详细介绍)
- -W
- -W[w][x][y][r]
指定加权回归以及将要提供的权重类型。
如果提供了 x 观测值的 1-\(\sigma\) 不确定度,请附加 x 。
如果提供了 y 的 1-\(\sigma\) 不确定度,请附加 y 。
如果提供了 x 和 y 观测值之间的相关性,请附加 r。这些列在输入中出现的顺序应紧随必选的 x 和 y 列之后。
同时给出 x 和 y (以及可选的 r )意味着进行正交回归。单独给出 x 需要配合使用
-Ex,单独给出 y 需要配合使用-Ey 。通过 \(w = 1/\sigma\) 的关系将 x 和 y 的不确定度转换为回归权重 w 。使用 -Ww 可以把输入列解释为预先计算好的权重。 注意 :相对于回归线的残差将根据给定的权重进行缩放。大多数范数随后会对此加权残差进行平方(
-N1 是唯一的例外)。
- -Z
- -Z[±]limit
更改离群值检测的阈值:当使用
-Nw 时,残差 z 分数(z-scores)超过此 limit [默认 ±2.5] 的点将被标记为离群值。 若要仅将负或正的 z 分数视为可能的离群值,请指定带符号的 limit 。
- -a
- -a[[col=]name][,...]
控制输入或输出为 OGR/GMT 格式时对非空间元数据的处理方式。 (参数详细介绍)
- -bi
- -bi[ncols][type][w][+l|b]
控制二进制文件的输入格式。 (参数详细介绍)
- -bo
- -bo[ncols][type][w][+l|b]
控制二进制文件的输出格式。 (参数详细介绍)
- -d
- -d[i|o]nodata
将某些特定值当作 NaN。 (参数详细介绍)
- -e
- -e[~]"pattern" | -e[~]/regexp/[i]
筛选或剔除匹配指定模式的数据记录。 (参数详细介绍)
- -f
- -f[i|o]colinfo
显式指定当前输入或输出数据中每一列的数据类型。 (参数详细介绍)
- -g
- -g[a]x|y|d|X|Y|D|[col]zgap[+n|p]
确定数据或线段的间断。 (参数详细介绍)
- -h
- -h[i|o][n][+c][+d][+msegheader][+rremark][+ttitle]
在读/写数据时跳过文件开头的若干个记录。 (参数详细介绍)
- -i
- -icols[+l][+sscale][+ooffset][,...][,t[word]]
对输入的数据进行列选择以及简单的代数运算。 (参数详细介绍)
- -o
- -ocols[,...][,t[word]]
对输出的数据进行列选择以及简单的代数运算。 (参数详细介绍)
- -q
- -q[i|o][~]rows[+ccol][+a|f|s]
对输入或输出的行进行筛选,该选项在一定程度上可以代替 gawk 的某些功能。 (参数详细介绍)
- -s
- -s[cols][+a|+r]
设置 NaN 记录的处理方式。 (参数详细介绍)
- -w
- -wy|a|w|d|h|m|s|cperiod[/phase][+ccol]
将输入坐标转换为循环坐标。 (参数详细介绍)
- -^ 或 -
显示简短的帮助信息,包括模块简介和基本语法信息(Windows下只能使用 -)
- -+ 或 +
显示帮助信息,包括模块简介、基本语法以及模块特有选项的说明
- -? 或无参数
显示完整的帮助信息,包括模块简介、基本语法以及所有选项的说明
- --PAR=value
临时修改GMT参数的值,可重复多次使用。参数列表见 配置参数
ASCII 格式精度
ASCII 格式输出数据通过 gmt.conf 配置文件控制。控制经纬度格式的参数为 FORMAT_GEO_OUT ;控制绝对时间的的参数包括 FORMAT_DATE_OUT 和 FORMAT_CLOCK_OUT ;普通浮点数通过参数 FORMAT_FLOAT_OUT 控制。上述格式控制可能会导致精度损失,这会在下游计算中导致一些问题。 如果用户需要保证数据精度,则应考虑将数据写为二进制文件,或者使用 FORMAT_FLOAT_OUT 指定更多的有效数字。
注意事项
输出的分段头 (segment header) 将包含我们为每个分段计算的各种统计数据。
其顺序依次为: N (点数)、 x0 (加权平均值 x)、 y0 (加权平均值 y)、 angle (直线角度)、 E (不拟合度量)、 slope (斜率)、 intercept (截距)、 sigma_slope 以及 sigma_intercept 。
对于标准回归 ( -Ey ),还会报告皮尔逊相关系数 r 和判定系数 R 。最后以有效测量数 \(n_{eff}\) 结束。
对于加权数据,在计算需要最小化的平方回归不拟合度量 -N2 时,使用:
其中有效测量数由下式给出:
因此 \(\nu = n_{eff} - 2\) 是有效自由度。
对于涉及除直线拟合之外更通用的线性模型回归,请参阅 math -A 以及 LSQFIT 或 SVDFIT 算子。
示例
返回通过远程文件 hertzsprung-russell.txt 中数据的最佳拟合正交回归线坐标:
gmt regress @hertzsprung-russell.txt -Eo -Fxm
对 points.txt 中的 x-y 数据进行标准最小二乘回归,并返回 x、y 以及带有 99% 置信区间的模型预测值:
gmt regress points.txt -Fxymc -C99 > points_regressed.txt
若只想获取上述回归的斜率:
slope=`gmt regress points.txt -Fp -o5`
对数据 rough.txt 进行重新加权最小二乘回归,并返回 x、y、模型预测值以及 RLS 权重:
gmt regress rough.txt -Fxymw > points_regressed.txt
对数据 crazy.txt 进行正交最小二乘回归,但先对 x 和 y 取对数,然后返回 x、y、模型预测值和标准化残差 (z-scores):
gmt regress crazy.txt -Eo -Fxymz -i0-1l > points_regressed.txt
对于同一文件,检查正交 LMS 不拟合度量在 0 到 90 度之间(步长 0.2 度)如何随角度变化:
gmt regress points.txt -A0/90/0.2 -Eo -Nr > points_analysis.txt
强制正交 LMS 选择具有正斜率的最佳解:
gmt regress points.txt -A+fp -Eo -Nr > best_pos_slope.txt
参考文献
Bevington, P. R., 1969, Data reduction and error analysis for the physical sciences, 336 pp., McGraw-Hill, New York.
Draper, N. R., and H. Smith, 1998, Applied regression analysis, 3rd ed., 736 pp., John Wiley and Sons, New York.
Rousseeuw, P. J., and A. M. Leroy, 1987, Robust regression and outlier detection, 329 pp., John Wiley and Sons, New York.
York, D., N. M. Evensen, M. L. Martinez, and J. De Basebe Delgado, 2004, Unified equations for the slope, intercept, and standard errors of the best straight line, Am. J. Phys., 72(3), 367-375.